
前端开发必须掌握的基本概念
编译型(compiled) VS 解释型(interpreted)
计算机语言
通常分为三类:即机器语言,汇编语言和高级语言
机器语言(machine language)
(1)概念:机器语言是用二进制代码(0 和 1)表示的、计算机能直接识别和执行的一种机器指令的集合。它是计算机的设计者通过计算机的硬件结构赋予计算机的操作功能。
(2)特点:不同种类的计算机其机器语言是不兼容的,按某种计算机的机器指令编制的程序不能在另一种计算机上执行。在现今,除了计算机生产厂家的专业人员外,绝大多数程序员已经不再学习机器语言。
(3) 示例

图 1 机器语言
(4)指令集架构
又称指令集或指令集体系(英语:Instruction Set
Architecture,缩写为 ISA),是计算机体系结构中与程序设计有关的部分,包含了基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部 I/O。指令集架构包含一系列的 opcode 即操作码(机器语言),以及由特定处理器执行的基本命令。
计算机微处理器的指令集架构(Instruction Set Architecture)常见的有两种:
精简指令集运算(Reduced Instruction Set
Computing,RISC):该指令集较为简单,每个指令的运行时间较短,完成的操作也简单,指令的执行性能较佳;但是要做复杂的事情,就需要由多个指令配合完成。当前有 UNIX、Linux、MacOS 以及包括 iOS、Android、WindowsPhone、WindowsRT 等在内的大多数移动操作系统运行在精简指令集的处理器上。
复杂指令集运算(Complex Instruction Set
Computing,CISC):与 RISC 不同的是,CISC 在指令集的每个小指令可以执行一些较低级的硬件操作,指令数目多而且复杂,每条指令的长度不同。因为指令执行较为复杂,所以每条指令花费的时间较长,但每个指令可以处理的工作较为丰富。常见的 CISC 指令集的 CPU 有 AMD、intel、VIA 等 X86 架构的 CPU。当前 x86 架构微处理器如 Intel 的 Pentium/Celeron/Xeon 与 AMD 的 Athlon/Duron/Sempron;以及其 64 位扩展系统的 x86-64 架构的 Intel
64 的 Intel Core/Core2/Pentium/Xeon 与 AMD64 的 Phenom II/Phenom/Athlon
64/Opteron/Ryzen/EPYC 都属于复杂指令集。主要针对的操作系统是微软的 Windows 和苹果公司的 OS
X。另外 Linux,一些 UNIX 等,都可以运行在 x86(复杂指令集)架构的微处理器。
参考:https://www.processon.com/view/link/5dad48c8e4b0e4339303ebe2
汇编语言(assembly language)
概念:是用与代码指令实际含义相近的英文缩写词、字母和数字等符号来取代指令代码的一种符号语言(汇编语言亦称符号语言)。所以说,汇编语言是一种用助记符表示的仍然面向机器的计算机语言。
特点:机器语言和汇编语言都是面向硬件(CPU)的语言,语言对机器过分依赖。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。使用汇编语言编写的源代码,然后通过相应的汇编程序将它们转换成可执行的机器代码。这一过程被称为汇编过程。
(3)示例:如用 ADD 表示运算符号“+”的机器代码
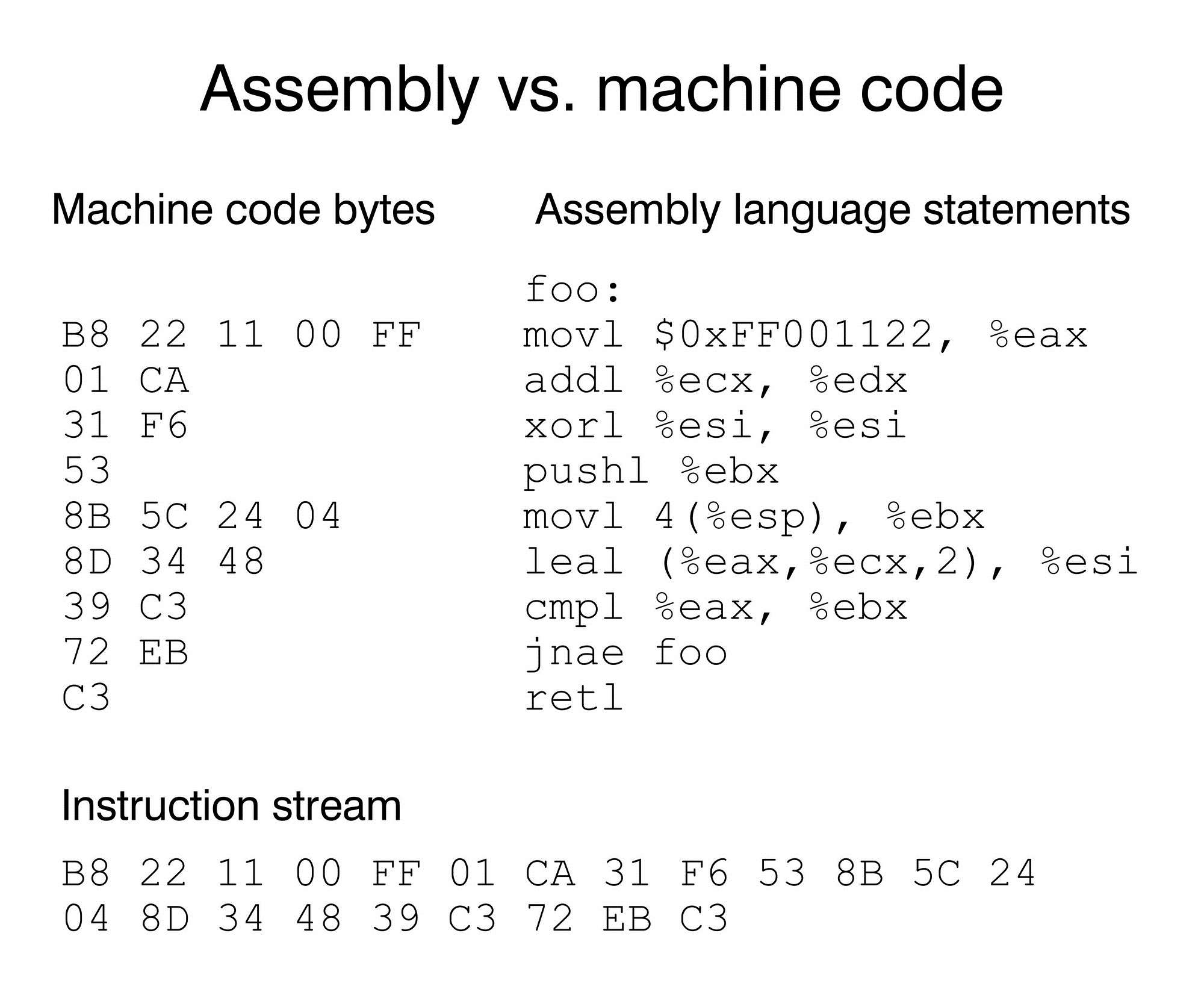
图 2 汇编语言
高级语言(High-level programming language)
(1)概念:高级编程语言是高度封装了的编程语言。它是以人类的日常语言为基础的一种编程语言,使用一般人易于接受的文字来表示,有较高的可读性,以方便对电脑认知较浅的人亦可以大概明白其内容。由于早期电脑业的发展主要在美国,因此一般的高级语言都是以英语为蓝本。
(2)示例:现在开发人员使用的大部分都是高级语言,如 Java、JavaScript、Python 等等
(3)特点:高级语言是面向用户的语言。无论何种机型的计算机,
只要配备上相应的高级语言的编译或解释程序,则用该高级语言编写的程序就可以通用
编译型语言和解释型语言
分类依据
根据高级程序语言的运行方式不同,分为两种:编译型语言和解释型语言
根本区别:把高级语言编译成机器语言,执行这个编译过程的时机不同,即运行方式不同
概念
(1)编译型语言
在程序运行之前
:使用针对特定 CPU 体系的编译器,将源代码(高级程序语言编写的代码)一次性的编译成目标代码(机器语言编写的代码)(源代码——机器码);程序运行时,直接运行编译好的目标代码;
再次运行时,可直接使用上一次编译好的机器码,不需要重新编译。
(2) 解释型语言
程序运行时:即边编译边运行,每编译一行程序(高级语言——机器语言),就立刻运行,然后再编译下一行,再运行,如此不停地进行下去;
再次运行时,需要重新进行编译。
(3)比较
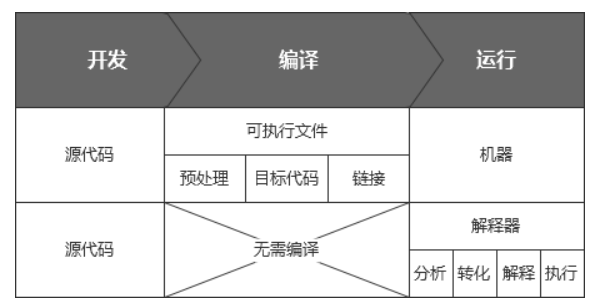
图 3 高级语言执行过程
用解释器来运行程序会比直接运行编译过的机器代码来得慢,但是相对的这个解释的行为会比编译再运行来得快。这在程序开发的雏型化阶段和只是撰写试验性的代码时尤其来得重要,因为这个“编辑-解释-调试”的循环通常比“编辑-编译-运行-调试”的循环来得省时许多。所以解释型语言可以达到较快的开发速度,编译型语言可以达到较快的运行进度之间。
常用语言分类
编译型语言:C、C++
解释型语言:JavaScript、Python、MATLAB、TypeScript
总结
编译型与解释型,两者各有利弊。
Java 语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和 Java 源代码之间的中介代码,运行的时候则由 JVM(Java 的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。
既然编译型与解释型各有优缺点又相互对立,所以一批后来诞生的语言都有把两者折衷起来的趋势。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。
其他概念
【源程序】又叫源码,用非机器语言书写好的符号程序称源程序
【目标程序】指源程序经编译后可直接被不同 CPU 架构运行的机器码集合
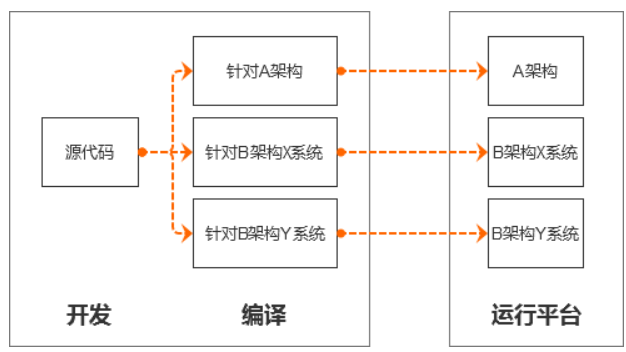
图 4 编译器
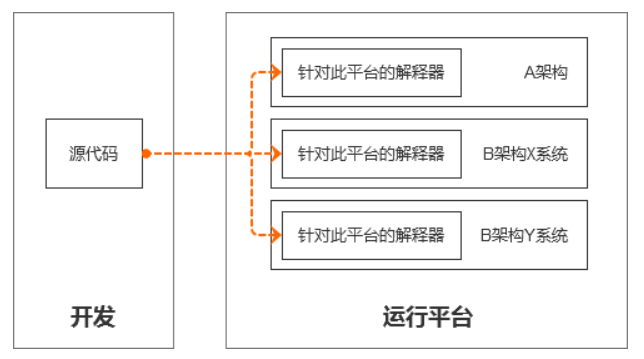
图 5 解释器
转自:*https://blog.csdn.net/qq_41026740/article/details/96009765*
https://www.cnblogs.com/clemente/p/10413618.html
静态类型(Static Typing) VS 动态类型(Dyn amic Typing)
分类标准
编程语言里会有类型检查的机制,类型检查的目的是避免程序发生一些未预料到的错误。
编程语言按照类型检查可以分为两大类:静态类型和
动态类型。二者的根本区别在于:进行类型检查的时机,类型检查可以理解为:确定变量的类型,并实行类型的约束操作(类型转换)
概念
- 静态类型
在运行前进行数据类型检查的语言,即静态类型语言中,变量的类型必须先声明,即在创建的那一刻就已经确定好变量的类型
- 动态类型
在程序运行时才做数据类型检查的语言,即动态类型语言中,声明变量时无需指定类型,第一次将某类型的数据赋值给变量,在内部会将数据类型记录下来,成为该变量的类型
【注意】静态类型在编译型语言中较为普遍,动态类型在解释型语言中较为普遍,但不是绝对的,如 TypeScript 是解释型语言,静态类型语言
讨论
静态类型在程序运行前,就能可靠地发现类型错误。因此通常能增进最终程序的可靠性。然而,有多少的类型错误发生,以及有多少比例的类型错误能被静态类型所捕捉,目前对此仍有争论。静态类型的拥护者认为,当程序通过类型检查时,它才有更高的可靠性。但是动态类型的拥护者指出,大部分软件证明,两者在可靠性上并没有多大差别。
常用语言分类
静态类型语言:Java、C、C++、TypeScript
动态类型语言:JavaScript、Python
【补充】前端最常用见的 10 个错误中,有 7 个是类型错误,ts 它是静态类型语言。在没运行的时候,IDE 就帮我们做类型检查了,能减少错误,所以前端开发就这方面而言 ts 优于 js。
转自:https://www.jianshu.com/p/bc492fcbf18f
强类型(Strong Typing) VS 弱类型(Weak Typing)
分类标准
按编程语言对类型检查的严格程度的强弱之分:分为强类型定义语言和弱类型定义语言
概念
- 强类型语言
一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了
2、弱类型语言
对于变量类型的检查比较宽松,容忍隐式类型转换这种事情的发生,包括相关类型之间隐式转换和不相关类型之隐式间转换
常用语言分类
强类型语言:Python、Java、C#
弱类型语言:JavaScript、TypeScript
【注意点】“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的
例如:
Python 是动态语言,是强类型定义语言(类型安全的语言)
JavaScript 是动态语言,是弱类型定义语言(类型不安全的语言)
JAVA 是静态语言,是强类型定义语言(类型安全的语言)
对强弱类型的深入理解
虽然对这两个词是这样定义的,但是在技术含义上这两个术语尚未达成共识。相比之下,静态类型化意味着程序在执行之前就经过检查,程序可能在启动前被拒绝。动态类型化意味着在执行过程中会检查值的类型,而类型错误的操作可能会导致程序停止运行或在运行时发出错误信号。静态类型化的主要原因是要排除可能具有此类“动态类型错误”的程序。
强类型通常意味着类型系统中没有漏洞,而弱类型意味着类型系统可以被破坏。但是 C 语言,在编译时对语言进行类型检查(静态类型),但是仍然存在很多漏洞。几乎可以将任何类型的值转换为相同大小的另一类型,特别是可以自由地转换指针类型。
所以不同的人对“强”和“弱”两个程度副词的理解和定义是不同的。所以避免使用这两个词对语言做区分。
转自:https://blog.csdn.net/m0_37828249/article/details/87971474
集成开发环境(IDE(IntegratedDevelopmentEnvironment)) VS 编辑器(Editor)
概念
1、编辑器
就是基于对一个文件、一个视频、一串数字等进行编辑或者再次编辑的工具。一般是为了文件、视频或者字符有更好的体现功能才进行的编辑,总的来说大概就是修改与编写的意思,可编写代码,也可编写文字,编辑图片等。常见的编辑器有文本编辑器、网页编辑器、源程序编辑器、图像编辑器,声音编辑器,视频编辑器等
示例:Notepad++等
2、IDE
集成开发环境(IDE,Integrated Development Environment
),是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。编译器、编辑器、调试器都可以属于 IDE,如微软的 Visual
Studio 系列,Borland 的 C++
Builder、Delphi 系列等。该程序可以独立运行,也可以和其它程序并用。IDE 多被用于开发 HTML 应用软件。
简单说,就是集成了编辑器、编译器以及链接器等众多功能的一个集成开发环境。
示例:Visual Studio 系列、webstorm 等(vs code 加上它一大堆插件)
转自:https://blog.csdn.net/pointer_5/article/details/94242888
语法糖(Syntactic sugar) VS 语法盐(syntactic salt)
概念
- 语法糖
语法糖是在不改变其所在位置的语法结构的前提下,实现了运行时等价。可以简单理解为,加糖后的代码编译后跟加糖前一模一样,只是更方便程序员使用,让程序更加简洁,有更高的可读性
示例:ES6 的箭头函数、解构赋值等
2、语法盐
语法盐是指那些为避免容易犯的语法错误加上的额外语法限制。这些特性强迫程序员做出一些基本不用于描述程序行为,而是用来证明他们知道自己在做什么的额外举动。
示例:
类型检查
有人建议在用 end if, end while 等代替现在的统一的 end
C++ 通过引入 static_cast、reinterpret_cast、const_cast 和 dynamic_cast
这四种转换来强迫程序员多敲键盘,从而令他们少用转换C#在 switch 语法中的 case 标记代码块内,如果没有 goto、return、throw 跳离语法,一定得加上 break 语法
如果非常仔细、小心,这些语法盐可能就是多余的
转自:https://segmentfault.com/a/1190000010159725
重复发明轮子(Reinvent the wheel)
来源
我们都知道轮子应该是圆的最省力,但是当我们的祖先不知道什么形状最省力的情况下,就可能会发明出三角轮、四边轮、五边轮等等。当大家都知道圆形的轮子是最省力的,是最好的形状之后,再发明其他形状的轮子就没有什么意义了。当大家都知道圆形的轮子是最省力的、是最好的形状之后,如何改进现有的圆形轮子,才是最重要的。
为什么是轮子
因为轮子是人类历史上最伟大的发明之一。轮子是人类的早期发明物之一。早期的轮子,是光滑的圆木,人们借助于这些圆木在地面上移动物体。历史上没有记录表明轮子是在什么年代、由谁发明的。然而,当“第一个发明者”把轮子安装在轴上时,人们就开始利用轮子把物体从一个地方移动到另一个地方。人们发现,在公元前 2000 年埃及古文物中,便有了轮子;古代中国文明也有发明使用轮子的记载和考古发现。
尽管轮子如此强烈地吸引着人类,可是人们却花费了几个世纪的时间来建造使用轮子的机器,而且大约有 400 多年,轮子的基本形状一直没有变化。
概念
- 概念
是指前人已经指明了方向,我们需要了解之前轮子的原理和利弊,加以改进或修改,使它更好或者满足自己新的需求。
2、示例
Linus 在上大学的时候,他觉得老师教学用的操作系统 Minix 不够好用,于是就自己写了一个操作系统来代替,这东西就叫 Linux,市场份额占到了服务器市场的一半甚至更多在与其他人开发 Linux 的过程中,他们一直使用的版本控制系统 Bitkeeper 终止了授权,而 Torvalds 觉得其他的版本控制系统太蠢了,于是花了一周又自己写了一个东西,叫做 Git。于是这个东西又占到了版本控制系统市场的七成甚至八成以上的份额。
脚手架(Scaffolding)
概念
在计算中使用的脚手架指的是两种技术之一:
第一种是与某些 MVC 框架中的数据库访问相关的代码生成技术;
第二种是由各种工具支持的项目生成技术。
“脚手架”是一种元编程的方法,用于构建基于数据库的应用。许多 MVC 框架都有运用这种思想。程序员编写一份 specification(规格说明书),来描述怎样去使用数据库;而由(脚手架的)编译器来根据这份 specification 生成相应的代码,进行增、删、改、查数据库的操作。我们把这种模式称为”脚手架”,在脚手架上面去更高效的建造出强大的应用。
前端开发中脚手架的作用是创建项目的初始文件,本质是方案的封装。前端工程体系的功能涵盖范围广,封装的方案类型多,对应的配置项也非常复杂。而且,大多数前端工程体系的开发者并不是一线的业务开发者。对于业务开发者来说,这套工程体系就是一个黑盒,他们不需要了解其中的复杂原理,只需要知道如何配置即可。所以业务开发者的需求就是快速开发快速配置,并且生成的配置项跟项目要对应,既要满足项目的功能需求,又不能有“混淆视听”的冗余功能。
CLI(command-line interface)
CLI 为 command-line interface 的缩写,意为:命令行界面,是脚手架的实现方式之一。Vue
CLI 是一个 Vue.js
快速开发的完整系统(或者俗称为:命令行工具),它所具有的一项功能是:快速搭建繁杂的单页面应用。
vue 的 cli
vue 是一套渐进式(就是你需要什么就用什么,不需要什么就可以不用,强制你遵守的规则很少),自底向上增量开发(就是根据系统和硬件编写出基层的基本需求代码,再慢慢增加模块),由于他要求遵守的规则较少,你可以引不同自己需要的东西,就需要配合 webpack 打包工具把引入的不同模块的东西打包
webpack 是一个工具,俗称打包工具,就是把所以浏览器不能识别的东西如(less,scss)等转换为浏览器可以识别的语言如(css),因为 vue 中需要引入大量的各种各样的模块
所以很依赖 webpack 。在 webpack 看来 一切皆模块。
cli 他能快速生成 webpack 打包结构,就跟‘!’可以动态生成 html 框架一样。
转自:https://blog.csdn.net/pojpoj/article/details/100737194
银弹(Silver Bullet)
来源
在古老的传说里,狼人是不死的。想要杀死狼人有几种方法:
1.像杀死吸血鬼那样用木桩钉住狼人的心脏;
2.将月光遮住
3.用银子做的子弹射穿透狼人的心脏或头
当然现实中是没有狼人的。但现实中确实有银弹这个东西。而其意义也类似于能杀死狼人的最好办法。现实中的狼人可以是一个棘手的项目,或者一件不可能的事。而“银弹”就是指能解决这些事的方法,或者技术手段。如果看过《人月神话》,那一定对银弹这个词并不陌生。不过在 IT 行业中,只有张嘴不办事的人会去幻想银弹技术。《没有银弹》(No
Silver Bullet)是 IBM 大型电脑之父佛瑞德·布鲁克斯(Fred
Brooks)在 1987 年所发表的一篇关于软体工程的经典论文。该论述中强调由于软体的复杂性本质,而使真正的银弹并不存在;所谓的没有银弹是指没有任何一项技术或方法可使软件工程的生产力在十年内提高十倍。
概念
本意是指万金油、万能药、一个完美的解决方案。在软件开发中,银弹是指使得使生产率、可靠性或简洁性获得数量级上的进步。但是软件开发本身具备复杂性,不可见性,可变性,随着计算机历史的发展,软件开发次要困难从很大程度上已经得到解决,但从某种程度上来说,无论怎么发展,软件本身具有的复杂性都没有从根本上得到解决。
转自:*https://www.zhihu.com/question/20829469*
https://www.zhihu.com/question/20829469/answer/16319016
Shim VS polyfill
概念
- shim
shim 一般指一些做兼容性的库,
用来弥补旧浏览器对新特性支持的不足。它将一个新的 API 引入到一个旧的环境中,而且仅靠旧环境中已有的手段实现,即把不同 API 封装成一种。
- polyfill
一个 polyfill 就是一个用在浏览器 API 上的 shim,也是·对浏览器的不足做补充。但是它的做法是先检查当前浏览器是否支持某个 API,如果不支持的话就加载对应的 polyfill.然后新旧浏览器就都可以使用这个 API 了
示例:旧浏览器不支持 ES6 的 Array.prototype.find 方法,我们想要在项目中使用
Array.prototype.find,
Shim:function arrayFind() { if (Array.prototype.find) {// … } else {// … }}
Polyfill:if (!Array.prototype.find) { Array.prototype.find = function() {// …
}}
转自:https://www.jianshu.com/p/26d34cebf6be?utm_source=oschina-app
库 (library) VS 框架(framework)
概念
1、库
库是一系列预先定义好的数据结构和函数(对于面向对象语言来说,是类)的集合,提供给开发者使用,程序员通过使用这些数据结构和函数实现功能。库没有控制权,控制权在使用者手中,在库中查询需要的功能在自己的应用中使用。
2、框架
框架也是一系列预先定义好的数据结构和函数,一般用于作为一个软件的骨架,会基于自身的特点向用户提供一套相当于叫完整的解决方案,而且控制权的在框架本身,使用者要找框架所规定的某种规范进行开发。
本质区别
框架与库之间最本质区别在于控制权:you call libs, frameworks call
you(控制反转)
联系和区别
二者联系紧密,他们以聚合的形式让我们在所要开发的应用中使用,在框架中我们完全可以自由的使用库,同时也可以没有框架的基础之上使用库,使用库的控制权始终在我们的手中,但是使用框架时候就必须按照它的规范来进行模块化的开发。
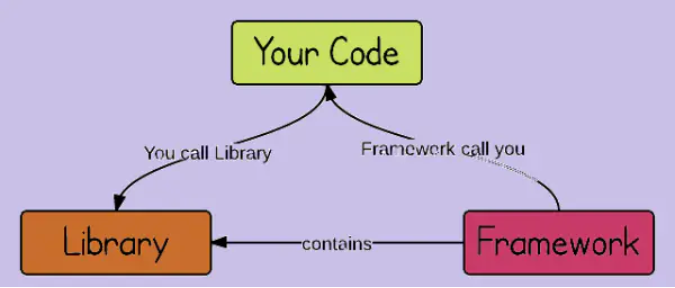
图 6 库和框架的关系
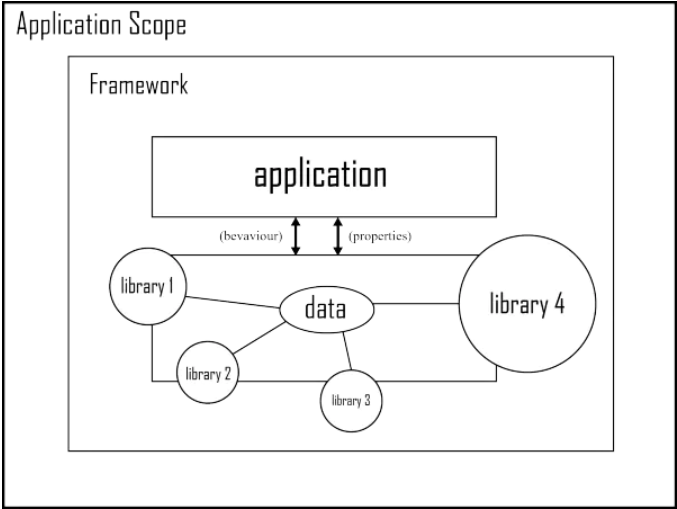
图 7 应用、库和框架的关系
转自:*https://www.jianshu.com/p/60100985dd7f*
方法(method ) VS 函数(function)
函数属于整个文件, 方法属于某一个对象,函数可以直接调用,
方法必须用对象或者类来调用
URL VS URI VS URN
概念
1、URI:Uniform Resource Identifier,统一资源标识符
URI 是以某种统一的(标准化的)方式标识资源的简单字符串,一般由三部分组成:
(1)访问资源的命名机制。
(2)存放资源的主机名。
(3)资源自身的名称,由路径表示
2、URL:Uniform Resource Locator,统一资源定位符
URL 是 Internet 上用来描述信息资源的字符串,主要用在各种 WWW 客户程序和服务器程序上。采用 URL 可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。 URL 的格式由下列三部分组成:
(1)协议(或称为服务方式);
(2)存有该资源的主机 IP 地址(有时也包括端口号);
(3)主机资源的具体地址。如目录和文件名等。
第一部分和第二部分之间用”://”符号隔开,第二部分和第三部分用”/”符号隔开。第一部分和第二部分是不可缺少的,第三部分有时可以省略。
- URN:Uniform Resource Name,统一资源名称
URN 是用特定命名空间的名字标识资源
联系和区别
- 联系
URL 和 URN 都是 URI 的一种,URI 的范畴位于体系的顶层,URL 和 URN 的范畴位于体系的底层。这种排列显示 URL 和 URN 都是 URI 的子范畴。
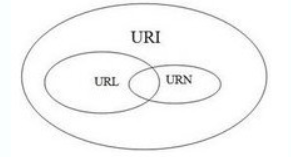
图 8 三者的关系
- 不同
URI 指的是一个资源,URL 是用地址定位一个资源,URN 是用名称定位一个资源
转自:https://www.cnblogs.com/wxlzhizu/archive/2010/06/04/1751517.html
localStorage VS sessionStorage
概念
localStorage 和 sessionStorage 一样都是用来存储客户端临时信息的对象,他们均只能存储字符串类型的对象(虽然规范中可以存储其他原生类型的对象,但是目前为止没有浏览器对其进行实现)
异同点
相同点
存储大小都是 5MB
都保存在客户端,不与服务端交互通信
只能存储字符串类型,对于复杂的对象可以使用 ECMAScript 提供的 JSON 对象的 stringify 和
parse 来处理
不同点
生命周期不同
localStorage 生命周期是永久,关闭页面或浏览器之后 localStorage 存储的数据也不会丢失,除非用户显式地在浏览器提供的 UI 上清除 localStorage 信息,否则这些信息将永远存在
sessionStorage 生命周期为当前窗口或标签页,一旦窗口或标签页被永久关闭了,那么所有通过 sessionStorage 存储的数据也就被清空了
- 数据共享机制
不同浏览器无法共享 localStorage 或 sessionStorage 中的信息。
相同浏览器的不同页面间可以共享相同的 localStorage(页面属于相同域名和端口)
不同页面或标签页间无法共享 sessionStorage 的信息。这里需要注意的是,页面及标
签页仅指顶级窗口,如果一个标签页包含多个 iframe 标签且他们属于同源页面,那么他们之间是可以共享 sessionStorage 的。
转自:https://www.cnblogs.com/vickylinj/p/10883256.html
向前兼容(Foreward Compatibility) VS 向后兼容(Backward Compatibility)
概念
兼容包括:硬件兼容性和软件兼容性
Forward 意思是向前进,指未来,向前兼容是站在旧版本的立场讨论未来版本的兼容性问题。在计算机中指在较低档计算机上编写的程序,可以在同一系列的较高档计算机上运行,或者在某一平台的较低版本环境中编写的程序可以在较高版本的环境中运行,都称为向上兼容,前者是硬件兼容,而后者是软件兼容。向上兼容具有非常重要的意义,一些大型软件的开发,工作量极大,如这些软件都能做到兼容,则无需在其它机器上重新开发,就可节省庞大的人力和物力。
Backward 意思是向后退,指过去,站在新版本的立场讨论过去版本的兼容性问题。在计算机中指在一个程序或者类库更新到较新的版本后,旧的版本程序创建的文档或系统仍能被正常操作或使用,或在旧版本的类库的基础上开发的程序仍能正常编译运行的情况。例如较高档的计算机或较高版本的软件平台可以运行较为低档计算机或早期的软件平台所开发的程序。向下兼容可以使用户在进行软件或硬件升级时,厂商不必为新设备或新平台从头开始编制应用程序,以前的程序在新的环境中任然有效。
转自:https://blog.csdn.net/wangxufa/java/article/details/72846362
正向代理(Forward proxy) VS 反向代理(Reverse proxy)
网络代理分为正向代理和反向代理。
正向代理
(1)概念
当客户端无法访问外部资源的时候,可以通过一个正向代理去间接地访问,所以客户端需要配置代理服务器的 ip。
正向代理是一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须设置正向代理服务器,当然前提是要知道正向代理服务器的 IP 地址,还有代理程序的端口。
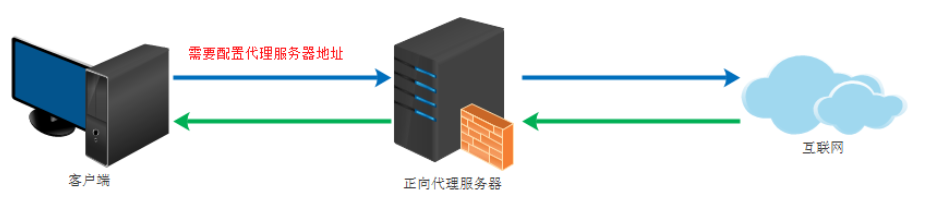
图 9 正向代理
(2)举例
我是一个用户,我访问不了某网站,但是我能访问一个代理服务器,这个代理服务器呢,他能访问那个我不能访问的网站,于是我先连上代理服务器,告诉他我需要那个无法访问网站的内容,代理服务器去取回来,然后返回给我。从网站的角度,只在代理服务器来取内容的时候有一次记录,有时候并不知道是用户的请求,也隐藏了用户的资料,这取决于代理告不告诉网站。
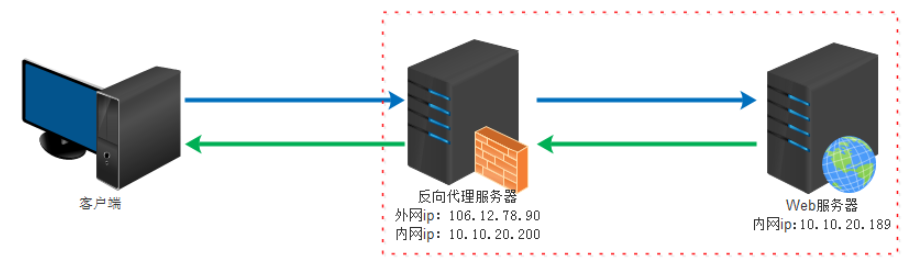
图 10 反向代理
- 作用
访问原来无法访问的资源,如 google
可以做缓存,加速访问资源
对客户端访问授权,上网进行认证
代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理
- 概念
反向代理实际运行方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。客户端是感知不到代理的存在的,反向代理对外都是透明的,访问者者并不知道自己访问的是一个代理。因为客户端不需要任何配置就可以访问。
- 作用
保证内网的安全,可以使用反向代理提供 WAF 功能,阻止 web 攻击大型网站,通常将反向代理作为公网访问地址,Web 服务器是内网
负载均衡,通过反向代理服务器来优化网站的负载
转自:https://www.jianshu.com/p/a1c35f5d27f7
ES6 VS ES2015
ECMAScript 和 JavaScript 的关系
ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现。
JavaScript 是 Netscape 创造的并交给了国际标准化组织 ECMA,之所以不叫做 JavaScript 由于商标的问题,java 是 sun 公司的商标,根据授权协议只有 Netscape 公司可以合法使用 JavaScript 这个名字,另外就是为了体现 JavaScript 的标准的制定者不是 ECMA 所以取名为 ECMAScript
ECMAScript 的历史
ECMAScript 1.0 是 1997 年发布的,接下来的两年,连续发布了 ECMAScript 2.0(1998
年 6 月)和 ECMAScript 3.0(1999 年 12 月)。3.0
版是一个巨大的成功,在业界得到广泛支持,成为通行标准,奠定了 JavaScript
语言的基本语法,以后的版本完全继承。直到今天,初学者一开始学习
JavaScript,其实就是在学 3.0 版的语法。
2000 年,ECMAScript 4.0 开始酝酿。这个版本最后没有通过,但是它的大部分内容被 ES6
继承了。因此,ES6 制定的起点其实是 2000 年。
为什么 ES4 没有通过呢?因为这个版本太激进了,对 ES3
做了彻底升级,导致标准委员会的一些成员不愿意接受。2008 年 7
月,由于对于下一个版本应该包括哪些功能,各方分歧太大,争论过于激烈,ECMA
开会决定,中止 ECMAScript 4.0 的开发,将其中涉及现有功能改善的一小部分,发布为
ECMAScript
3.1,而将其他激进的设想扩大范围,放入以后的版本,由于会议的气氛,该版本的项目代号起名为
Harmony(和谐)。会后不久,ECMAScript 3.1 就改名为 ECMAScript 5。
ES6 与 ECMAScript 2015 的关系
ES6 是 ECMA 的为 JavaScript 制定的第 6 个版本的标准,标准委员会最终决定,标准在每年的 6
月份正式发布一次,作为当年的正式版本。ECMAscript 2015
是在 2015 年 6 月份发布的 ES6 的第一个版本。依次类推 ECMAscript 2016 是 ES7、 ECMAscript
2017 是 ES8……,最新的是 ECMAscript 2019,即 ES10
转自:https://es6.ruanyifeng.com/#docs/intro
进程(process) VS 线程(thread)
进程和线程是操作系统的基本概念
概念
进程:是执行中一段程序,即一旦程序被载入到内存中并准备执行,它就是一个进程。进程是表示资源分配的的基本概念,又是调度运行的基本单位,是系统中的并发执行的单位。
线程:单个进程中执行中每个任务就是一个线程。线程是进程中执行运算的最小单位。
从 CPU 运行的角度理解
CPU+RAM+各种资源(比如显卡,光驱,键盘等等外设)构成我们的电脑,但是电脑的运行,实际就是 CPU 和相关寄存器以及 RAM 之间的事情。
执行一段程序代码,实现一个功能的过程是:当得到 CPU 的时候,相关的资源必须也已经就位,然后 CPU 开始执行。这里除了 CPU 以外所有的就构成了这个程序的执行环境,也就是我们所定义的程序上下文。当这个程序执行完了,或者分配给他的 CPU 执行时间用完了,那它就要被切换出去,等待下一次得到 CPU。在被切换出去的最后一步工作就是保存程序上下文,因为这个是下次他得到 CPU 的运行环境,必须保存。
所以计算机工作的过程是:先加载程序 A 的上下文,然后开始执行 A,保存程序 A 的上下文,调入下一个要执行的程序 B 的程序上下文,然后开始执行 B,保存程序 B 的上下文。
进程和线程就是这样的背景出来的,两个名词是对应的 CPU 时间段的描述。进程就是包换上下文切换的程序执行时间总和,即 CPU 加载上下文、CPU 执行、CPU 保存上下文之和。进程的颗粒度太大,每次都要有上下的调入,保存,调出。如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序 A,实际分成
a,b,c 等多个块组合而成。那么这里具体的执行就可能变成:程序 A 得到 CPU
,然后 CPU 加载上下文,开始执行程序 A 的 a 小段,然后执行 A 的 b 小段,然后再执行 A 的 c 小段,最后 CPU 保存 A 的上下文。这里 a,b,c 的执行是共享了 A 的上下文,CPU 在执行的时候没有进行上下文切换的。这里的 a,b,c 就是线程,也就是说线程是共享了进程的上下文环境,的更为细小的 CPU 时间段。
二者关系
(1)根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
(2)资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
(3)包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
(4)内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
(5)影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
(6)执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
转自:https://blog.csdn.net/ThinkWon/java/article/details/102021274
https://blog.csdn.net/ThinkWon/article/details/102021274
参考:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
形参(parameter) VS 实参 (argument)
概念
1、实参
全称为”实际参数”,是在调用时传递给函数的参数。实参可以是常量、变量、表达式、函数等
2、形参
全称为”形式参数”
由于它不是实际存在变量,所以又称虚拟变量。是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数
VR(Virtual Reality)VS AR(Augmented Reality) VS MR(Mixed Reality)
概念
1、VR(虚拟现实)
是指利用计算机技术模拟产生一个为用户提供视觉、听觉、触觉等感官模拟的三度空间虚拟世界,用户借助特殊的输入/输出设备,与虚拟世界进行自然的交互。用户进行位置移动时,电脑可以通过运算,将精确的三维世界视频传回产生临场感,令用户及时、无限制地观察该空间内的事物,如身临其境一般。
简单地说,VR 看到的图像全是计算机模拟出来的,都是虚假的
2、AR(增强现实)
是一种实时计算摄影机影像位置及角度,并辅以相应图像的技术。这种技术可以通过全息投影,在镜片的显示屏幕中将虚拟世界与现实世界叠加,操作者可以通过设备互动。
AR 是将虚拟信息加在真实环境中,来增强真实环境,因此看到的图像是半真半假,如 Faceu 激萌特效相机 APP,这款 APP 会自动识别人脸,并在人脸上叠加动态贴图和道具,从而创造出卖萌搞笑效果的照片,例如加兔子耳朵、加彩虹特效
3、MR(混合现实)
指的是结合真实和虚拟世界创造了新的环境和可视化三维世界,物理实体和数字对象共存、并实时相互作用,以用来模拟真实物体,是虚拟现实技术的进一步发展。
MR 是将真实世界和虚拟世界混合在一起,可以说它呈现的图像令人真假难辨
三者关系
VR 概念最小,AR 概念包含了 VR,MR 概念最大,包含了 VR 和 AR
AR 和 MR 的辨别
虚拟物体与真实物体是不是被肉眼分离出来,如果不能被肉眼分离的就是 MR,可以的就是 AR。例如之前提到的 Faceu 激萌特效相机 APP 以及不少 AR 应用一眼就可以知道哪些是真的,哪些是假的。而 MR 直接向视网膜投射整个 4 维光场,所以用户看到的物体和看真实的物体,从数学上是没有区别的。
转自:*https://www.sohu.com/a/203516748_100033040*
yarn VS npm
二者都是 JS 依赖包管理工具,Yarn 是由 Facebook,google,Exponent 和 Tilde
制作的一种新的 JavaScript 软件包管理器。可以在官方公告上看到,其目的是解决团队在
npm 面临的问题,即安装包不够快、有安全隐患,npm 允许安装包执行代码。
npm 的问题
npm install 的时候非常慢,删除 node_modules,重新 install 的时候依旧如此;
同一个项目,安装的时候无法保持一致性。由于 package.json 文件中版本号的特点,下面三个版本号在安装的时候代表不同的含义。

图 11 npm 版本控制
“5.0.3”表示安装指定的 5.0.3 版本,“~ 5.0.3”表示安装 5.0.X 中最新的版本,“^5.0.3”表示安装 5.X.X 中最新的版本。这就会导致同一个项目,由于安装的版本不一致出现 bug。
- 安装的时候,包会在同一时间下载和安装,中途某个时候,一个包抛出了一个错误,但是 npm 会继续下载和安装包。因为 npm 会把所有的日志输出到终端,有关错误包的错误信息就会在一大堆 npm 打印的警告中丢失掉,使得不太容易注意到实际发生的错误。
yarn 的优点
1、速度快,速度快主要来自以下两个方面:
(1)并行安装:无论 npm 还是 Yarn 在执行包的安装时,都会执行一系列任务。npm
是按照队列执行每个 package,也就是说必须要等到当前 package
安装完成之后,才能继续后面的安装。而 Yarn 是同步执行所有任务,提高了性能。
(2)离线模式:如果之前已经安装过一个软件包,用 Yarn 再次安装时之间从缓存中获取,就不用像 npm 那样再从网络下载了。
2、安装版本统一
为了防止拉取到不同的版本,Yarn 有一个锁定文件 (lock file)
记录了被确切安装上的模块的版本号。每次只要新增了一个模块,Yarn
就会创建(或更新)yarn.lock
这个文件。这么做就保证了,每一次拉取同一个项目依赖时,使用的都是一样的模块版本。
3、更简洁的输出
npm 的输出信息比较冗长。在执行 npm install <package>
的时候,命令行里会不断地打印出所有被安装上的依赖。相比之下,Yarn
简洁太多:默认情况下,结合了
emoji 直观且直接地打印出必要的信息,也提供了一些命令供开发者查询额外的安装信息。
转自:https://www.jianshu.com/p/254794d5e741
K VS P(Progressive)
我们在下载电影时,通常有标清、高清、全高清甚至超高清的源,再细心一点我们会发现它们分别又叫 480p、720p、1080p…,那么这些数字背后意味着什么,K 和 p 又分别代表什么含义?
概念
P 是 Progressive,逐行的意思,P 是逐行扫描,表示的是“视频像素的总行数”,几 P 就是纵向有多少行像素,例如,1080p 就是纵向有 1080 行像素,1080x1080(1:1),1440x1080(1.33),1920x1080(1.78),2581x1080(2.39),3840x1080(3.56)等都是 1080P
K 表示的是“视频像素的总列数”,
“几 K”的原始定义是:横向大约有几个 1024 列像素,1K 就是 1024,2K 就是 2048,4K 就是 4096,以此类推。但在电视领域,这些“几 K”都被加上了一个固定分辨率标准,比如 2K 是 2560x1440,4K 是 3840x2160,大家平时所说的这些所谓标准,都是 16:9 的电视标准(TV
Standard)K”和“P”能否同时出现?要想准确描述一个屏幕或视频的分辨率,这两者必须同时出现,否则就会出现歧义
电视标准仅仅只在电视领域或日常生活中 16:9 的视频和显示器比例中适用,一旦脱离了电视领域,或者屏幕及视频比例不再是 16:9,该规则即作废,定义一个视频有几 K 的方法只有一个:横向像素数有几个 1024,定义一个视频有几 P 的方法也只有一个:纵向有多少行像素
4K(超高清)、1080P(全高清)、720P(超清)、480P(高清)

